
At PASS Summit 2018 and SQL Saturday Oregon 2018, Angela Henry aka @SqlSwimmer on Twitter gave a presentation on Data Types Do Matter. Most of us have programmed stored procedures adding parameters without looking at the original datatype. Shortcuts are taken and the correct data type is not chosen, it will not matter. But will it?
A while ago, we contracted with a third party to start using their software and database with our product. We put the database in Azure but within a year, the database grew to over 250 gigs and we had to keep raising the Azure SQL Database to handle performance issues. Due to the cost of Azure, a decision was made to bring the database back on-premise. Before putting the database on the on-premise SQL Server, the server was running with eight CPUs. In production, we are running SQL Server 2016 Enterprise Edition. When we put the vendor database into production, we had to dramatically increase our CPUs in production, ending up with twenty-eight CPUs. Even with twenty-eight CPUs, during most of the production day, CPUs were running persistently at seventy-five percent. But why?
Query Store was on the database. We began to analyze Query Store to see why one additional database on the production server would drive our CPU usage so high. To see what was causing the issue, the most resource intensive query report in Query Store was run on the database and we saw this,
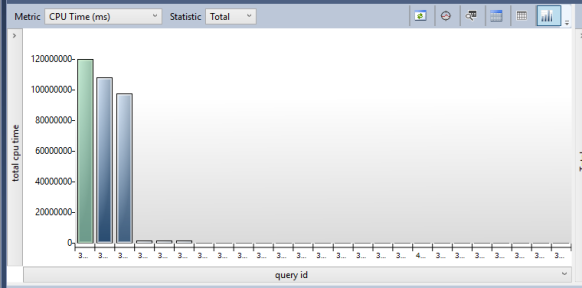
We found the queries which were causing the CPU issues. By highlighting one of the graphs, you can view the query plan the query is using in the window pane to the right of this window pane in Query Store. You will see one or more dots showing you the query plan but the real magic is hovering your mouse over one of the dots to see how the query was actually performing. Below is what I saw when I hovered over the query plan dot,

In one hour, the most resource intensive query ran eighty-three thousand one hundred and ninety-four times. Wow, this query runs a lot and it is using a ton of CPU time per hour. In the bottom pane of the Query Store, we see the execution plan. Looking at the execution plan, I see one of the icons has a yellow yield warning symbol,

Lastly, if we right click on the icon and look at the properties of the icon, toward the bottom of the detail property screen, we see that the query is having a problem with implicit conversion,

The information was passed back to the vendor to fix their code. The vendor sent us a new release with the fix for implicit conversion. Upon deploying the change to production, we had a massive reduction in CPU usage. From twenty-eight CPUs running persistently at seventy-five percent usage down to eight CPUs running persistently at less than thirty percentage usage. Shocking, never thought implicit conversion could cause such a wide variance in CPU usage.
As Angela says, Data Types Do Matter!
